
참고: 이 데이터는 Hugging Face에서 운영하는 LMSYS Chatbot Arena 에서 최근에 각동 LLM 모델들을 평가한 자료를 Claude 3로 분석하여 설명한 내용입니다. 아래 그래프나 도표는 모두 이 LMSYS Chatbot Arena 사이트에서 발췌한 것입니다.
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
LMSYS Chatbot Arena는 다양한 LLM(Large Language Model)의 성능을 종합적으로 평가하고 비교하기 위한 오픈 플랫폼입니다. 이 플랫폼에서는 크라우드소싱을 통해 수집한 사용자들의 선호도 평가 데이터를 바탕으로 모델 간 상대적 우열을 가리고 있습니다. 40만명이 넘는 사람들의 선호도 투표를 모아 Elo 랭킹 시스템으로 LLM을 순위화했습니다.
부연 설명:
- LMSYS Chatbot Arena Leaderboard 는 대규모 언어모델(LLM)의 성능을 평가하기 위한 플랫폼입니다.
- 이 플랫폼은 크라우드소싱 방식으로 운영되며, 누구나 참여할 수 있는 오픈 플랫폼입니다.
- 40만명 이상의 사람들이 직접 LLM들에 대한 선호도를 투표했습니다.
- 이 투표 결과를 바탕으로 Elo 랭킹 시스템을 적용하여 LLM들의 순위를 매겼습니다.
- Elo 랭킹 시스템은 전통적으로 체스 등 두 플레이어 간 경기에서 실력 차이를 수치화하는 데 사용되는 방식입니다.
- 이 경우에는 사람들의 선호도 투표를 통해 LLM 간 상대적 성능 차이를 Elo 점수로 계산했습니다.
결론적으로 종합하면 현재로서는 Claude 3 opus와 GPT-4 계열 모델이 여러 평가 지표에서 최고 성적을 거두며 LLM 시장을 선도하고 있다고 평가할 수 있겠습니다. Bard, Claude 3 sonnet 등이 그 뒤를 바짝 추격하고 있으며, 구형 모델들과는 분명한 격차를 보이고 있습니다.

주요 평가 항목과 그 의도를 살펴보면 다음과 같습니다:
1. 일대일 대결 승률 (Figure 1):
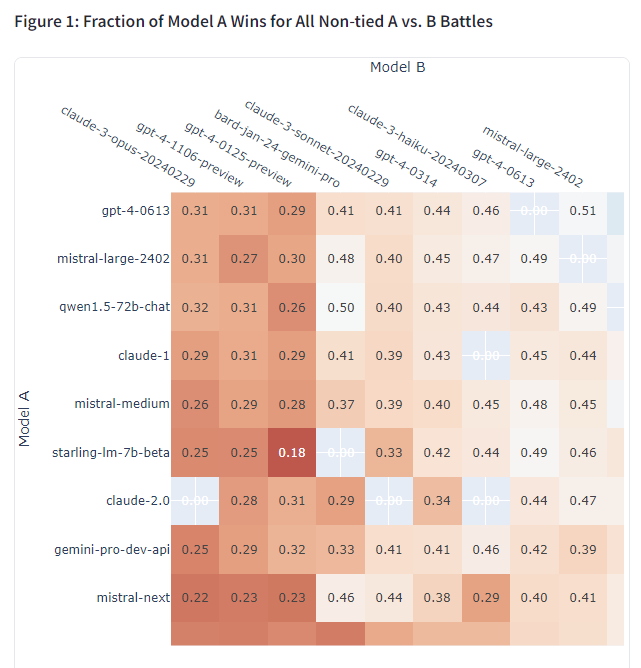
- 각 모델 쌍 간의 일대일 대결에서의 승패 결과를 집계하여 승률을 계산한 것입니다.
- 개별 모델 간의 상대적 우열 관계를 직관적으로 살펴볼 수 있습니다.
- 특정 모델이 다른 모델에 비해 어느 정도의 우위를 점하는지 파악할 수 있습니다.
2. 대결 횟수 분포 (Figure 2):
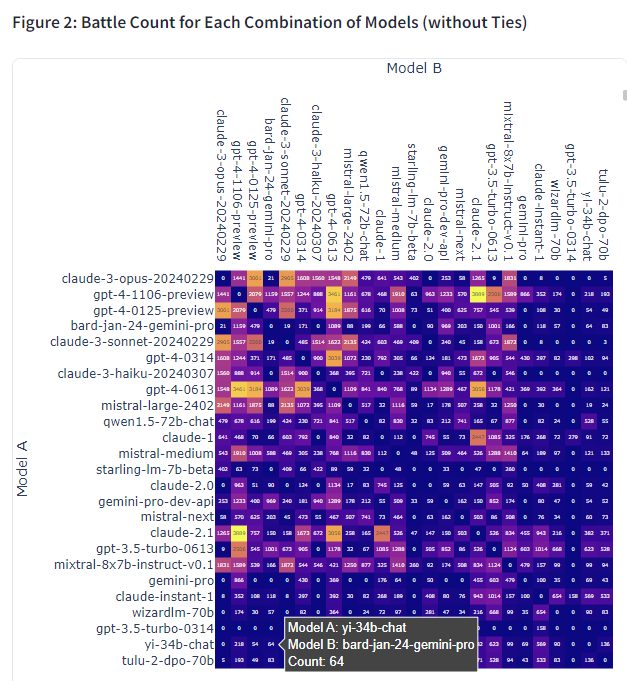
- 각 모델 쌍 간에 몇 번의 대결이 이루어졌는지를 히트맵 형태로 제시한 것입니다.
- 단순히 승률뿐 아니라 평가 데이터의 양도 모델 평가에 중요한 요소임을 고려한 것으로 보입니다.
- 대결 횟수가 적은 모델의 경우 평가 결과의 신뢰도가 낮을 수 있음을 시사합니다.
3. Elo 레이팅 (Figure 3):
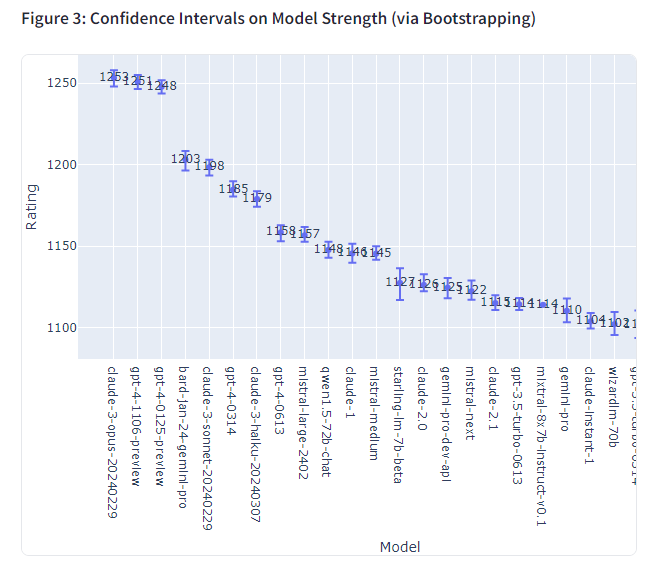
- 체스 등 경기에서 널리 사용되는 Elo 레이팅 시스템을 LLM 평가에 도입한 것입니다.
- 각 모델의 레이팅 점수와 신뢰구간을 산출하여 종합적인 성능 순위를 매기는 것이 목적입니다.
- 상대적으로 객관적이고 통계적으로 견고한 평가 결과를 제공하고자 했습니다.
4. 평균 승률 (Figure 4):
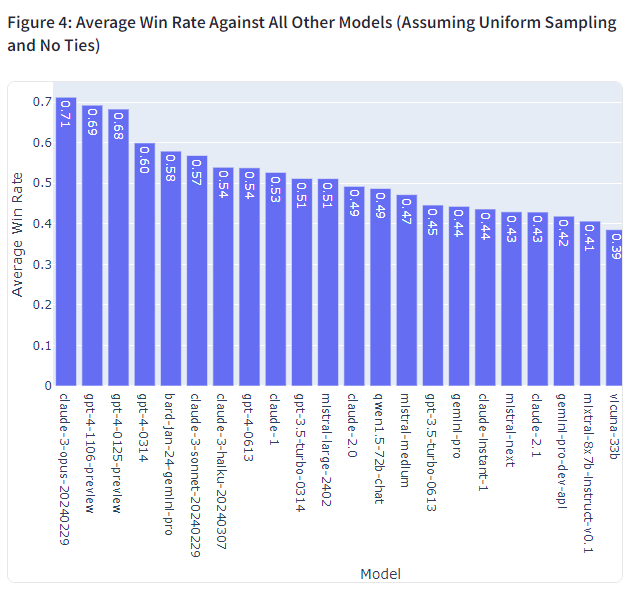
- 각 모델이 무작위로 선택된 상대와 대결할 때 기대되는 승률을 계산한 것입니다.
- 모델의 전반적인 경쟁력을 한 눈에 파악할 수 있는 지표로 활용될 수 있습니다.
- 특정 태스크나 도메인에 국한되지 않는 일반적인 성능 척도로서의 의미가 있습니다.
LMSYS Chatbot Arena의 다양한 평가 지표와 그래프를 종합해 보면, 현재 LLM 시장에서는 Anthropic의 Claude 3 모델과 OpenAI의 GPT-4 모델이 가장 우수한 성능을 보이고 있음을 알 수 있습니다.
개별 모델 간 일대일 대결 승률(Figure 1)에서도 Claude 3와 GPT-4 모델은 대부분의 상대 모델을 압도하는 모습을 보였습니다. 반면 구형 GPT 모델 등 하위권 모델들은 신형 모델들에게 고전하는 양상이 뚜렷했습니다. 평균 승률(Figure 4) 역시 Claude 3 opus가 71%로 가장 높았고, GPT-4와 Bard가 그 뒤를 이었습니다.
대결 횟수 분포(Figure 2)를 보면, 고성능 모델들 사이에서는 더 많은 대결이 이루어졌음을 알 수 있습니다. 이는 해당 모델들의 우열을 가리고 보다 정교한 성능 평가를 위해 더 많은 데이터를 수집하려 한 것으로 보입니다.
우선 Elo 레이팅과 그에 대한 신뢰구간(Figure 3)을 살펴보면, Claude 3 opus와 GPT-4 모델들이 1,250점 내외의 높은 점수를 기록했으며, 그 뒤를 Bard와 Claude 3 sonnet 등의 모델이 잇고 있습니다. 신뢰구간을 고려했을 때 상위 3~4개 모델과 하위권 모델 간에는 통계적으로 유의미한 성능 격차가 존재합니다.
다만 일부 중하위권 모델의 경우 대결 횟수가 적어 신뢰구간이 넓게 형성되어 있었습니다. 이들 모델의 정확한 실력을 가늠하기 위해서는 추가적인 데이터 수집과 평가가 필요할 것으로 보입니다.
이러한 다양한 평가 항목을 통해 Chatbot Arena는 LLM 모델들의 상대적 성능을 다각도로 분석하고, 사용자들에게 종합적인 평가 정보를 제공하고자 했습니다. 단순히 특정 태스크에서의 정확도나 속도를 넘어, 실제 사용자들이 느끼는 선호도와 만족도를 반영하려 한 것이 특징적입니다.
이는 급속도로 발전하는 LLM 기술 생태계에서 모델 간 경쟁 구도를 객관적으로 파악하고, 개발사들에게는 기술 개선의 방향성을 제시하며, 사용자들에게는 모델 선택의 가이드라인을 제공하려는 취지로 읽힙니다. 나아가 LLM 분야의 건전한 발전과 혁신을 촉진하는 데 기여하고자 하는 의도도 엿보입니다.
다만 평가 과정의 공정성과 투명성, 도메인 특화 태스크에 대한 고려, 평가 대상 모델의 확장성 등은 지속적으로 개선해 나가야 할 과제로 보입니다. Chatbot Arena가 LLM 평가의 글로벌 스탠다드로 자리매김하기 위해서는 이러한 과제들을 꾸준히 해결해 나가는 노력이 필요할 것입니다.
하지만 대부분의 평가 대상 모델이 아직 비공개 베타 단계인 만큼, 실제 서비스 상용화 국면에서는 API 안정성, 비용 대비 효율성 등 non-LLM적인 요소들도 경쟁력을 좌우할 것으로 예상됩니다. 기술력과 함께 생태계 구축 역량, 비즈니스 전략 등이 종합적으로 고려되어야 할 것입니다.
또한 평가 과정의 공정성과 투명성을 높이고, 다양한 태스크 특화 벤치마크를 추가하는 등 Chatbot Arena의 지속적인 진화도 필요해 보입니다. LLM 기술이 나날이 발전하는 만큼, 평가 체계 역시 더욱 정교화되어야 할 것입니다. 장기적 관점에서 지속적인 모니터링과 분석이 병행된다면 LLM 시장의 건전한 발전에 기여할 수 있을 것으로 기대합니다.
댓글
댓글 쓰기