시간이 지나면서 생성형 AI 모델은 급격히 발전하여, 자연어 이해 능력과 다단계 추론 기능이 크게 개선되었습니다. 이러한 기술적 진보는 프롬프트 엔지니어링의 필요성을 점차 줄이는 중요한 변화를 가져왔습니다. 과거에는 사용자가 원하는 답변을 얻기 위해 질문을 매우 세밀하게 구성해야 했습니다. 그러나 이제는 생성형 AI가 복잡한 질문도 스스로 논리적 단계를 나누어 추론하고 분석할 수 있는 능력을 갖추게 되었습니다.
예를 들어, "인서울 대학교들의 2025년도 대학입시 전형 중 2024년도와 비교해 달라진 점이나 새롭게 추가된 정책이 있는 학교들을 목록으로 만들어줘"라는 복합적인 질문을 예로 들어 보겠습니다.
과거 생성형 AI에 적용한 프롬프트 엔지니어링 방식
과거의 생성형 AI는 이처럼 복잡한 질문을 한 번에 이해하기 어려웠기 때문에, 사용자는 질문을 여러 단계로 나누어 프롬프트를 작성해야 했습니다. 사용자는 각 부분의 정보를 세분화하여 AI에게 순차적으로 물어봐야 했습니다.
단계 1: "2025년도 인서울 대학교의 대학 입시 전형 중 달라진 정책이 있는 학교들을 알려줘."
단계 2: "그렇다면 2024년도의 정책과 비교해서 달라진 사항을 설명해줘."
단계 3: "새롭게 추가된 정책이 있는 학교가 있는지 목록으로 보여줘."
이처럼 질문을 단계별로 분리하고, 각각의 질문에 구체적으로 답을 요구하는 방식이 필요했습니다. 프롬프트 엔지니어링이 요구되는 이유는 AI가 논리적 추론을 자동으로 수행하지 못했기 때문입니다. 그래서 사용자가 직접 단계를 분해하고 구체적인 조건을 명시해야만 AI가 적절한 답변을 줄 수 있었습니다.
현재 생성형 AI의 방식: 자동화된 다단계 추론
현재의 AI는 복잡한 질문도 스스로 논리적 단계를 나누어 처리할 수 있는 능력을 갖추고 있어, 사용자는 과거처럼 질문을 나누거나 구체적으로 분리할 필요가 없습니다. 단순히 한 번의 질문으로도 AI가 자동으로 질문을 분석하고, 필요한 세부 정보를 단계별로 수집하여 답변을 생성합니다.
현재 방식: "인서울 대학교들의 2025년도 대학입시 전형 중 2024년도와 비교해 달라진 점이나 새롭게 추가된 정책이 있는 학교들을 목록으로 만들어줘."
현재 AI는 이 질문의 맥락을 자동으로 이해하고, 2024년도의 정책과 2025년도를 비교하며, 필요한 경우 세부적인 추가 정보를 자동으로 추론합니다. 그 결과, AI는 사용자가 원했던 정보를 목록 형태로 종합하여 제공할 수 있게 되었습니다. 사용자는 더 이상 프롬프트를 세부적으로 조정할 필요가 없으며, 단순한 자연어 질문만으로도 충분히 복합적인 결과를 얻을 수 있습니다.
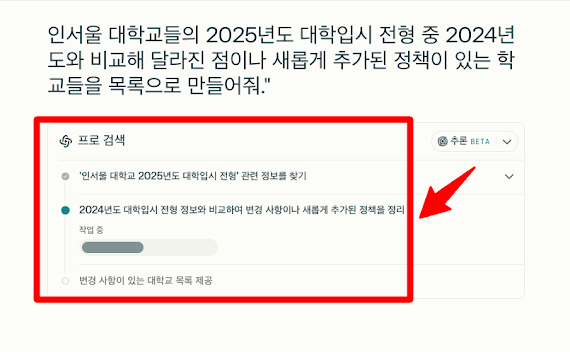
<Perplexity AI Pro 에서 멀티스텝 추론 검색의 예>
멀티 스텝 추론의 작동 방식의 원리 설명
특히 ChatGPT나 Perplexity AI와 같은 최신 모델들은 멀티스텝 추론을 통해 사용자의 질문을 자동으로 해석하고, 필요한 단계별 답변을 생성하는 데 능숙합니다. 사용자가 따로 복잡한 프롬프트를 작성할 필요가 없어졌습니다. AI가 알아서 맥락을 파악하고 답을 제공할 수 있게 된 것입니다. 이로인하여 AI의 비전문가들조차도 자연스럽게 AI와 상호작용할 수 있어서 기술 장벽을 대폭 낮추었습니다.
프롬프트 엔지니어링의 필요성 감소와 여전히 필요한 분야
생성형 AI의 발전은 프롬프트 엔지니어링의 필요성을 크게 줄였습니다. 과거에는 AI가 복잡한 질문을 제대로 이해하지 못했기 때문에, 사용자는 질문을 세밀하게 구성하고, 여러 단계로 나누어야만 했습니다. 하지만 최근 생성형 AI는 자연어 처리와 멀티스텝 추론 기능이 크게 향상되어, 복잡한 질문도 스스로 논리적 단계를 나누어 처리할 수 있게 되었습니다. 그러나 프롬프트 엔지니어링이 여전히 필요한 분야도 존재합니다. 특히 특화된 기술적 요구가 있는 분야에서는 여전히 프롬프트 엔지니어링이 중요한 역할을 합니다. 예를 들어:
전문적인 데이터 분석: 매우 구체적인 데이터 처리나 분석 작업에서는 여전히 사용자가 원하는 결과를 얻기 위해 프롬프트를 정교하게 구성해야 할 때가 있습니다. 예를 들어, 특정 금융 모델이나 통계 분석을 요청할 때는 AI가 자동으로 모든 맥락을 파악하기 어려울 수 있기 때문에, 사용자가 명확한 지침을 제공해야 합니다.
창의적 콘텐츠 생성: 광고 카피나 소설 작성과 같은 창의적인 작업에서 AI에게 특정한 스타일이나 어조를 요구할 때는 여전히 프롬프트 엔지니어링이 필요합니다. 사용자가 원하는 창의적 방향을 명확히 제시하지 않으면, 생성형 AI가 일반적이고 평범한 결과를 생성할 수 있습니다.
결론
생성형 AI의 발전으로 프롬프트 엔지니어링의 필요성은 점차 줄어들고 있습니다. 과거에는 생성형 AI가 복잡한 질문을 제대로 처리하지 못했기 때문에, 사용자가 질문을 세밀하게 구성하고 단계별로 나누어야만 했습니다. 하지만 오늘날의 생성형 AI는 멀티스텝 추론과 자연어 처리 능력이 크게 향상되어, 복잡한 질문도 스스로 논리적 단계를 나누어 처리할 수 있게 되었습니다. 이는 사용자 경험을 혁신적으로 변화시켰으며, 비전문가들도 간단한 자연어 질문만으로 AI의 강력한 기능을 활용할 수 있는 환경을 조성했습니다.
그러나 여전히 프롬프트 엔지니어링이 필요한 분야도 존재합니다. 예를 들어, 전문적인 데이터 분석이나 창의적 콘텐츠 생성과 같은 특수한 작업에서는 사용자가 원하는 결과를 얻기 위해 여전히 구체적이고 정교한 프롬프트가 필요할 수 있습니다. 이러한 분야에서는 AI가 모든 맥락을 자동으로 파악하기 어려운 경우가 많기 때문에, 사용자가 명확한 지침을 제공해야만 합니다.
결론적으로, 프롬프트 엔지니어링의 필요성은 특정 분야에서 여전히 존재하지만, 생성형 AI의 대중화와 일상적인 활용에 있어서는 그 필요성이 점차 줄어들고 있습니다. AI는 점점 더 복잡한 기술적 능력을 갖추면서도 사용자와의 상호작용은 오히려 간단하고 직관적으로 변하고 있습니다. 이는 AI가 더 많은 사람들에게 실질적인 유익을 제공할 수 있는 중요한 변화이며, 앞으로도 기술 발전에 따라 더욱 확산될 것입니다.
--------------------------------
Perplexity AI 활용 노하우 :
1. Perplexity AI 활용 노하우 대학 입시 해결 편
2.일상 생활 속 법률 문제 Perplexity AI 로 해결하는 방법
3. AI 검색 혁명 Perplexity 활용 완전 정복 (Yes24)
댓글
댓글 쓰기