생성형 AI의 혁신적 기능! "자연어 질의어로 SQL문을 생성한다고?”
Claude AI나 ChatGPT, Gemini와 같은 생성형 AI가 DB 스키마 정보만으로 자연어 질의와 SQL문을 생성할 수 있다는 것은 매우 흥미롭고 놀라운 기능입니다. 이로 인해 사용자들은 다음과 같은 이점을 얻을 수 있습니다.
1. 사용 편의성 향상
- 사용자가 SQL 문법을 숙지하지 않아도 자연어로 DB에 질의할 수 있습니다.
- 예를 들어, "지난 한 달간 가장 많이 팔린 제품 Top 5를 보여줘"라고 묻는 것만으로 AI가 자동으로 해당 SQL문을 생성해 줍니다.
2. 개발 속도 향상
- 개발자들이 일일이 SQL문을 작성할 필요 없이 자연어 질의만으로 원하는 데이터를 추출할 수 있어 개발 속도가 빨라집니다.
- 복잡한 JOIN이나 서브쿼리가 필요한 경우에도 AI가 자동으로 처리해 줍니다.
3. 비즈니스 인사이트 발굴
- 비개발자들도 쉽게 데이터를 탐색하고 분석할 수 있게 되어, 새로운 비즈니스 인사이트를 얻을 수 있습니다.
- 예컨대 마케터가 "신규 고객 유치율이 가장 높은 마케팅 채널 3개를 알려줘"라고 묻는 것만으로 고객 유치에 효과적인 채널을 파악할 수 있습니다.
이처럼 생성형 AI의 DB 스키마 기반 자연어 질의 및 SQL문 생성 기능은 기업의 데이터 활용을 혁신할 수 있는 엄청난 잠재력을 갖고 있습니다. 개발, 마케팅, 영업, 기획 등 다양한 분야에서 이 기술을 활용한다면 업무 효율성과 의사결정 속도를 크게 높일 수 있을 것입니다. 앞으로 많은 기업들이 이 놀라운 AI 기능을 경쟁적으로 도입하고 활용 사례를 만들어갈 것으로 기대됩니다.
Claude 를 활용한 DB 스키마 정보 이용 예시
샘플 DB 스키마는 엔트로픽 사이트에서 게시된 [1]전형적인 DB 스키마 (Customers, Products, Orders, Orders_Items, Reviews) 를 이용하였습니다.
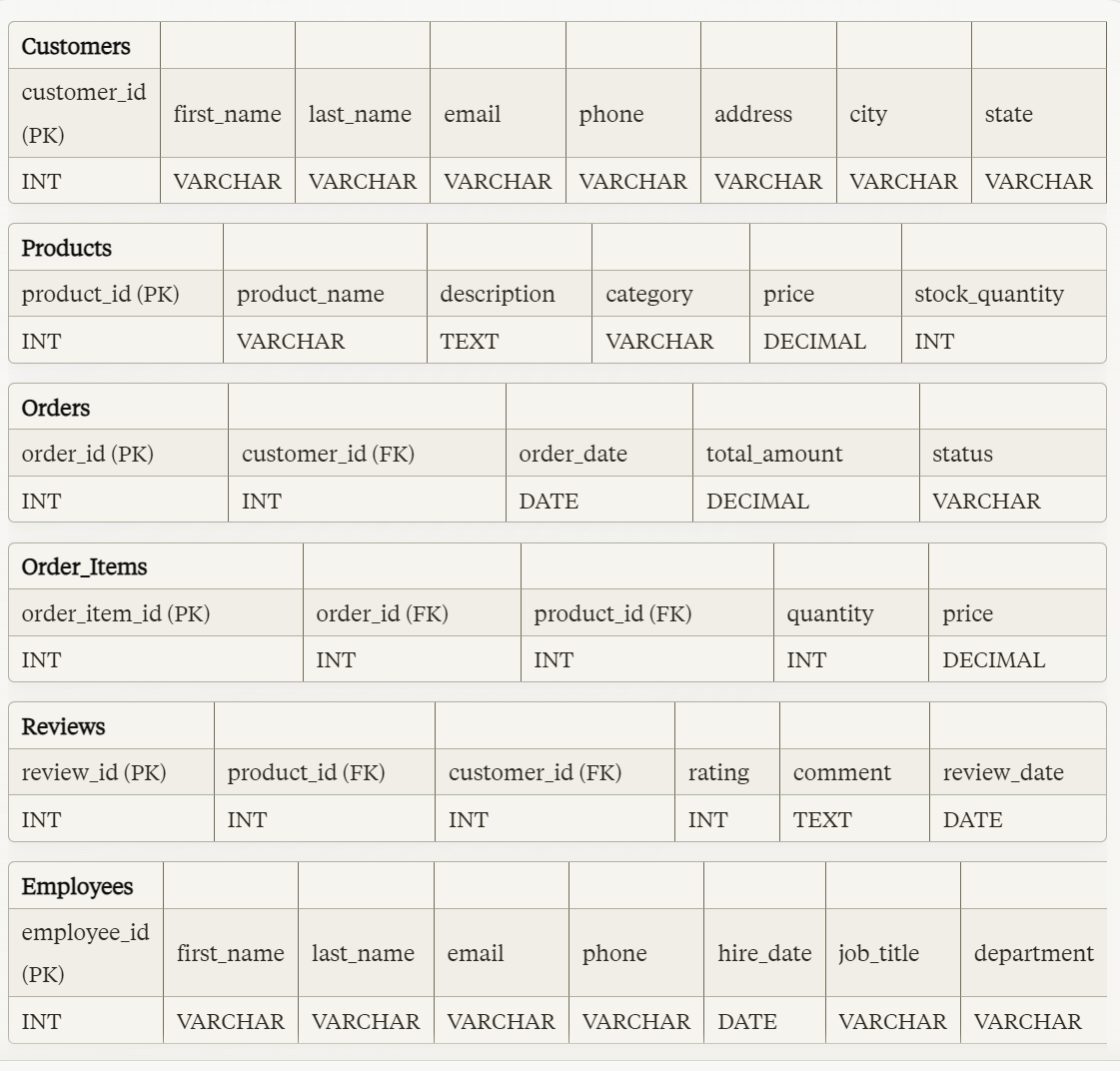
이 DB 스키마 웹 사이트 전체를 텍스트 복사한 후 이를 구글 Docs에 붙여 넣기 합니다. 이 구글 Docs에 저장된 내용을 PDF 파일로 내보기 한 후 이 PDF 파일을 Claude 에게 (또는 ChatGPT도 가능) 업로드한 후 ‘자연어 10개와 이에 맞는 SQL문을 표로 만들어줘’ 라고 명령하면 됩니다. 간단하지요.
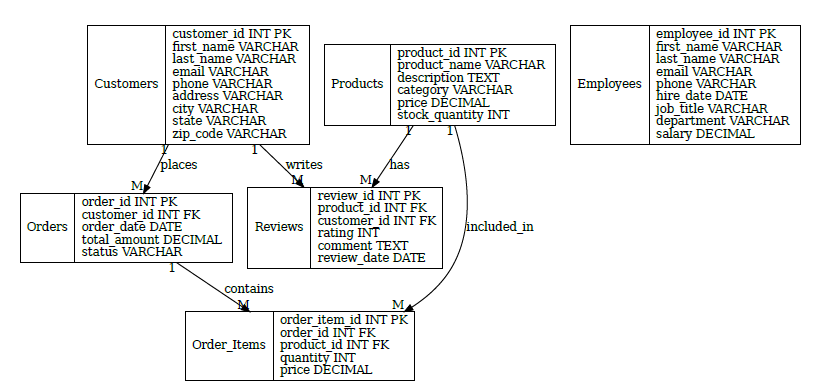
(** 이 ERD 그림은 Claude 에게 ‘업로드한 DB 스키마에 해당하는 ERD를 그리는 파이선 코드를 생성 해줘’ 한 후 Claude 가 생성한 파이선 코드를 복사하여 ChatGPT에서 실행한 결과입니다. **)
이렇게 하면 Claude는 이 스키마 정보를 바탕으로 다음과 같은 일을 할 수 있습니다:
1. 자연어 질의 이해
- 사용자의 자연어 질의에 등장하는 키워드를 DB 스키마의 테이블/컬럼명과 매칭합니다.
- 질의에 사용된 집계함수(SUM, AVG 등), 조건(최근 1년간, Top 10 등)을 파악합니다.
2. SQL문 생성
- 파악된 테이블/컬럼, 집계함수, 조건을 조합하여 올바른 문법의 SQL문을 자동 생성합니다.
- 필요한 경우 테이블 간 JOIN이나 서브쿼리도 사용합니다.
3. 데이터 타입 고려
- 컬럼의 데이터 타입(INT, VARCHAR, DATE 등)을 고려하여 적절한 연산과 비교를 수행합니다.
- 필요 시 문자열은 따옴표로 감싸고, 날짜는 데이터베이스에 맞는 포맷을 사용합니다.
4. 검증 및 정제
- 생성된 SQL문이 문법적으로 올바르고 실행 가능한지 검증합니다.
- 보안상 위험할 수 있는 내용(SQL Injection 등)은 제거합니다.
자연어 질의 20개와 해당 SQL문 예시
Claude Prompt:‘자연어 20개와 이에 맞는 SQL문을 표로 만들어줘’
Claude 답변:
자연어 질의 | SQL문 |
평균 주문금액이 $100 이상인 고객의 이메일 주소를 가져와줘 | SELECT email<br>FROM Customers<br>WHERE customer_id IN (<br> SELECT customer_id<br> FROM Orders<br> GROUP BY customer_id<br> HAVING AVG(total_amount) >= 100<br>); |
재고가 가장 적은 제품 카테고리 TOP 3를 보여줘 | SELECT category<br>FROM Products<br>GROUP BY category<br>ORDER BY SUM(stock_quantity) ASC<br>LIMIT 3; |
직원 급여에서 부서별 최고/최저 급여액을 보여줘 | SELECT department,<br> MAX(salary) AS max_salary,<br> MIN(salary) AS min_salary<br>FROM Employees<br>GROUP BY department; |
작년 동월 대비 매출 증가율이 가장 높은 달은 언제야? | WITH monthly_sales AS (<br> SELECT DATE_FORMAT(order_date, '%Y-%m') AS month,<br> SUM(total_amount) AS sales<br> FROM Orders<br> GROUP BY DATE_FORMAT(order_date, '%Y-%m')<br>)<br>SELECT month, sales,<br> LAG(sales) OVER (ORDER BY month) AS prev_sales,<br> sales / LAG(sales) OVER (ORDER BY month) - 1 AS growth<br>FROM monthly_sales<br>ORDER BY growth DESC<br>LIMIT 1; |
신규 가입 고객 비율이 제일 높은 도시 TOP 5는? | SELECT city, <br> COUNT(CASE WHEN YEAR(NOW()) = YEAR(first_order_date) THEN customer_id END) / COUNT(*) AS new_customer_ratio<br>FROM (<br> SELECT c.city, c.customer_id, MIN(o.order_date) AS first_order_date<br> FROM Customers c<br> JOIN Orders o ON c.customer_id = o.customer_id<br> GROUP BY c.city, c.customer_id<br>) AS t<br>GROUP BY city<br>ORDER BY new_customer_ratio DESC<br>LIMIT 5; |
주문건수가 가장 많은 요일 순위 | SELECT DAYNAME(order_date) AS day_of_week, COUNT(*) AS order_count<br>FROM Orders<br>GROUP BY DAYNAME(order_date)<br>ORDER BY order_count DESC; |
3월 주문 중 아직 미배송된 주문금액 합계는? | SELECT SUM(total_amount) AS undelivered_total<br>FROM Orders<br>WHERE status != 'Delivered'<br> AND YEAR(order_date) = YEAR(CURDATE())<br> AND MONTH(order_date) = 3; |
카테고리별로 재고 부족 제품 리스트(재고<10개)를 보여줘 | SELECT p.product_name, p.category, p.stock_quantity <br>FROM Products p<br>WHERE p.stock_quantity < 10<br>ORDER BY p.category, p.stock_quantity; |
가입 후 아무것도 주문하지 않은 휴면 고객은 몇명이지? | SELECT COUNT(*) AS dormant_customers<br>FROM Customers c<br>LEFT JOIN Orders o ON c.customer_id = o.customer_id<br>WHERE o.order_id IS NULL; |
제품별 평균 리뷰 점수와 리뷰 개수를 보여줘 | SELECT p.product_name, <br> AVG(r.rating) AS avg_rating,<br> COUNT(r.review_id) AS review_count<br>FROM Products p<br>LEFT JOIN Reviews r ON p.product_id = r.product_id<br>GROUP BY p.product_id, p.product_name; |
자연어 질의문 | SQL문 |
2022년에 주문한 고객의 이름, 이메일, 주문일자, 총 주문금액을 조회하세요 | SELECT c.first_name, c.last_name, c.email, o.order_date, o.total_amount<br>FROM Customers c<br>JOIN Orders o ON c.customer_id = o.customer_id<br>WHERE o.order_date BETWEEN '2022-01-01' AND '2022-12-31'; |
가장 많이 팔린 상위 5개 제품의 이름, 카테고리, 판매수량을 조회하세요 | SELECT p.product_name, p.category, SUM(oi.quantity) AS total_quantity<br>FROM Products p<br>JOIN Order_Items oi ON p.product_id = oi.product_id<br>GROUP BY p.product_id<br>ORDER BY total_quantity DESC<br>LIMIT 5; |
평균 평점이 4점 이상인 제품의 이름, 평균 평점, 리뷰 개수를 조회하세요 | SELECT p.product_name, AVG(r.rating) AS avg_rating, COUNT(r.review_id) AS review_count<br>FROM Products p<br>JOIN Reviews r ON p.product_id = r.product_id<br>GROUP BY p.product_id<br>HAVING AVG(r.rating) >= 4; |
주문 상태가 "Shipped"인 주문의 주문번호, 고객명, 주문일자, 총 주문금액을 조회하세요 | SELECT o.order_id, c.first_name, c.last_name, o.order_date, o.total_amount<br>FROM Orders o<br>JOIN Customers c ON o.customer_id = c.customer_id<br>WHERE o.status = 'Shipped'; |
2023년 상반기(1월6월) 매출 총액과 하반기(7월12월) 매출 총액을 각각 조회하세요 | SELECT<br> SUM(CASE WHEN order_date BETWEEN '2023-01-01' AND '2023-06-30' THEN total_amount ELSE 0 END) AS first_half_revenue,<br> SUM(CASE WHEN order_date BETWEEN '2023-07-01' AND '2023-12-31' THEN total_amount ELSE 0 END) AS second_half_revenue<br>FROM Orders<br>WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31'; |
"Electronics" 카테고리에 속하는 제품들의 평균 가격을 조회하세요 | SELECT AVG(price) AS avg_price<br>FROM Products<br>WHERE category = 'Electronics'; |
2023년 1분기(1월~3월) 주문에서 구매한 제품의 이름, 수량, 총 판매금액을 조회하세요 | SELECT p.product_name, SUM(oi.quantity) AS total_quantity, SUM(oi.quantity * oi.price) AS total_sales<br>FROM Products p<br>JOIN Order_Items oi ON p.product_id = oi.product_id<br>JOIN Orders o ON oi.order_id = o.order_id<br>WHERE o.order_date BETWEEN '2023-01-01' AND '2023-03-31'<br>GROUP BY p.product_id; |
고객별 총 주문금액이 1000달러 이상인 고객의 ID, 이름, 총 주문금액을 조회하세요 | SELECT c.customer_id, c.first_name, c.last_name, SUM(o.total_amount) AS total_order_amount<br>FROM Customers c<br>JOIN Orders o ON c.customer_id = o.customer_id<br>GROUP BY c.customer_id<br>HAVING SUM(o.total_amount) >= 1000; |
"New York"에 거주하는 고객 중 2023년에 주문한 고객의 이름, 이메일, 주문일자를 조회하세요 | SELECT c.first_name, c.last_name, c.email, o.order_date<br>FROM Customers c<br>JOIN Orders o ON c.customer_id = o.customer_id<br>WHERE c.city = 'New York' AND o.order_date BETWEEN '2023-01-01' AND '2023-12-31'; |
재고 수량이 10개 미만인 제품의 이름, 카테고리, 가격, 재고수량을 조회하세요 | SELECT product_name, category, price, stock_quantity<br>FROM Products<br>WHERE stock_quantity < 10; |
결론
Claude와 같은 생성형 AI가 DB 스키마 정보로부터 자연어 질의의 의도를 파악하고 그에 맞는 SQL문을 자동 생성할 수 있게 되면, 기업들은 개발 리소스를 크게 절약하면서도 데이터 활용도를 높일 수 있습니다.
비개발자들도 복잡한 쿼리를 직접 작성할 필요 없이 마치 동료에게 묻듯이 자연어로 데이터를 조회하고 분석할 수 있게 됩니다. 이는 데이터 민주화를 앞당기고, 보다 많은 구성원들이 데이터 기반의 의사결정을 내릴 수 있도록 도울 것입니다.
이 과정은 RAG(Retrieval-Augmented Generation)의 한 부분이 될 수 있습니다. RAG는 방대한 외부 지식을 활용하여 언어 모델의 생성 능력을 높이는 기술입니다. 질의에 필요한 정보를 외부 데이터베이스, 문서 등에서 찾아 언어 모델에 제공함으로써 보다 정확하고 풍부한 답변을 생성할 수 있게 됩니다.
DB 스키마와 데이터를 지식 소스로 활용한다면, 사용자의 질의에 대해 실제 DB에서 데이터를 검색하고 이를 바탕으로 SQL문과 답변을 생성하는 RAG 시스템을 구현할 수 있을 것입니다. 이는 단순히 SQL문을 생성하는 것을 넘어, 실제 DB 데이터와 연계된 보다 강력한 질의응답 시스템으로 발전할 수 있음을 시사합니다.
앞으로 AI 기술이 고도화되고 다양한 외부 지식과 결합되면서, 사용자의 복잡한 요구사항도 만족시킬 수 있는 종합적인 데이터 분석 및 질의응답 솔루션이 등장할 것으로 기대됩니다. 기업들은 RAG와 같은 첨단 AI 기술을 적극 도입하여 데이터 활용 경쟁력을 한층 더 높여나가야 할 것입니다.
댓글
댓글 쓰기