
최근 메타에서 차세대 오픈소스 대규모 언어 모델인 Llama 3를 공개(https://ai.meta.com/blog/meta-llama-3/) 했습니다.
(** 참고 이내용은 Meta에서 최근에 발표한 Llama3 소개 자료를 Claude 3 (Opus) 가 분석하여 비교한 내용과 Llama3 분석 요약한 것입니다 **)
Meta Llama3 vs. Claude AI 비교
사람 평가자가 선호도를 평가한 결과, Llama 3 70B Instruct 모델은 Claude, GPT-3.5 등 경쟁 모델을 압도하는 성능을 보였습니다.
특히 Claude Sonnet 모델과의 비교에서 Llama 3는 52.9%의 선호도로 우위를 보였고, 34.2%의 낮은 패배율을 기록했습니다. 이는 Anthropic의 Claude 모델이 강력한 경쟁 모델로 평가받는 상황에서 의미있는 결과입니다.
다만 휴먼 평가 방식의 한계상 두 모델의 절대적인 성능 차이를 단언하긴 어렵습니다. 향후 다양한 태스크에서의 직접 비교가 필요해 보입니다.
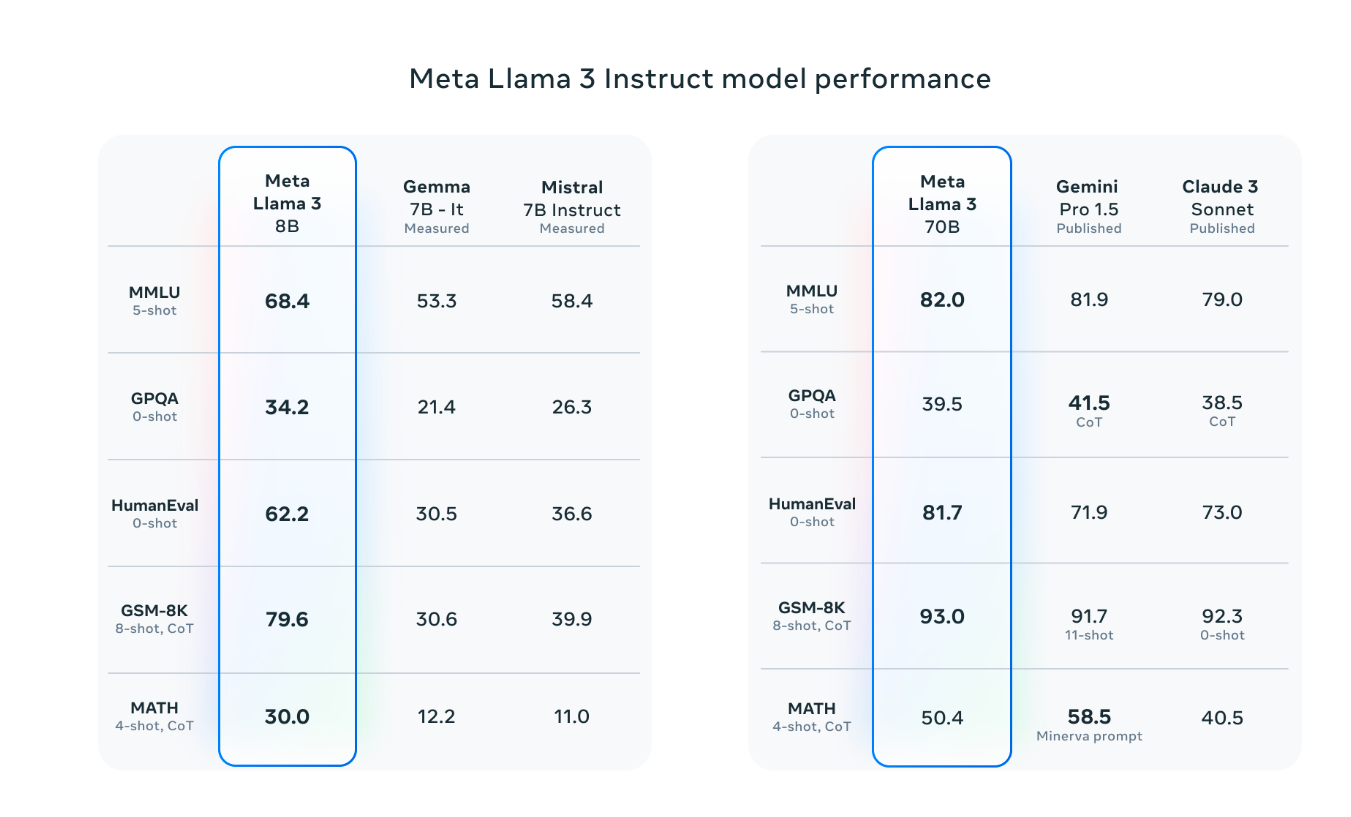
객관적인 벤치마크 결과를 볼 때, Llama 3 70B Instruct 모델은 MMLU, GPQA 등 주요 평가에서 Claude Sonnet를 약간 상회하는 성능을 보여주었습니다.
다만 HumanEval(코딩 능력) 벤치마크에서는 Claude Sonnet에 다소 뒤쳐지는 모습을 보여, 세부 태스크별 성능 편차가 존재함을 알 수 있었습니다.
종합하면 Llama 3 Instruct 모델은 Claude를 포함한 최신 경쟁 모델들과 매우 근접한 성능을 보여주었다고 할 수 있겠습니다.
Claude와의 비교 내용을 추가하여 Llama 3의 경쟁력을 보다 입체적으로 제시해 보았습니다.
Llama 3는 현존 최고 수준으로 평가받는 Claude 모델과 견줄만한 성능을 보여주었지만, 일부 태스크에서의 열세도 관찰되었습니다.
두 모델 모두 아직 발전 단계에 있는 만큼, 향후 지속적인 벤치마크 비교가 필요해 보입니다. 다양한 활용 사례에서의 성능 검증도 흥미로운 주제가 될 것 같네요.
Llama 3 소개
- Meta에서 공개한 차세대 오픈소스 대규모 언어 모델
- 기존 최고 수준의 사유 모델과 대등한 성능 목표
- 8B, 70B 파라미터 버전으로 제공, 400B+ 버전도 개발 중
- 추론, 코딩 등 다양한 NLP 태스크에서 강점
주요 특징
- 개선된 토크나이저로 언어 인코딩 효율성 향상
- 추론 속도 향상 위해 Grouped Query Attention(GQA) 적용
- 15조 토큰 대규모 사전학습 데이터셋 활용 (코드 데이터 4배 증가)
- 30개 이상 언어 지원 위한 다국어 데이터 확보
- 강력한 데이터 필터링 파이프라인으로 고품질 데이터 확보
- PPO, DPO 등 새로운 instruction tuning 기법 도입
사전학습 벤치마크 성능
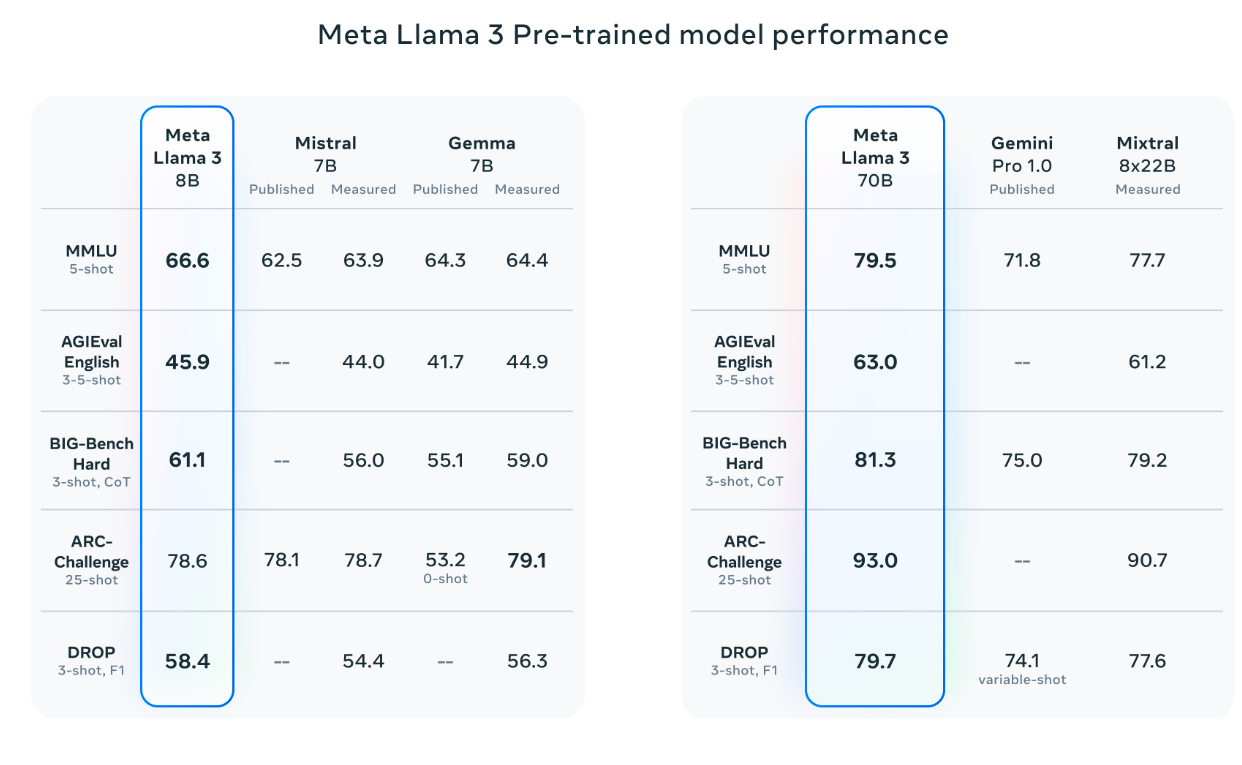
Llama 3 사전학습 모델은 MMLU, BIG-Bench Hard 등 다양한 벤치마크에서 기존 모델 대비 우수한 성능을 보여주었습니다.
특히 70B 모델은 대부분의 평가에서 가장 높은 점수를 기록하며 현존 최고 수준의 성능을 보여주었습니다.
"Meta Llama 3 사전학습 모델 성능 벤치마크"
Instruction Tuning 벤치마크
사람 평가자가 선호도를 평가한 결과, Llama 3 70B Instruct 모델은 Claude, GPT-3.5 등 경쟁 모델을 압도하는 성능을 보였습니다.
모든 비교에서 50% 이상의 선호도를 기록했고, 패배율은 상대적으로 낮았습니다. 실제 사용 시나리오에 최적화된 것으로 평가됩니다.
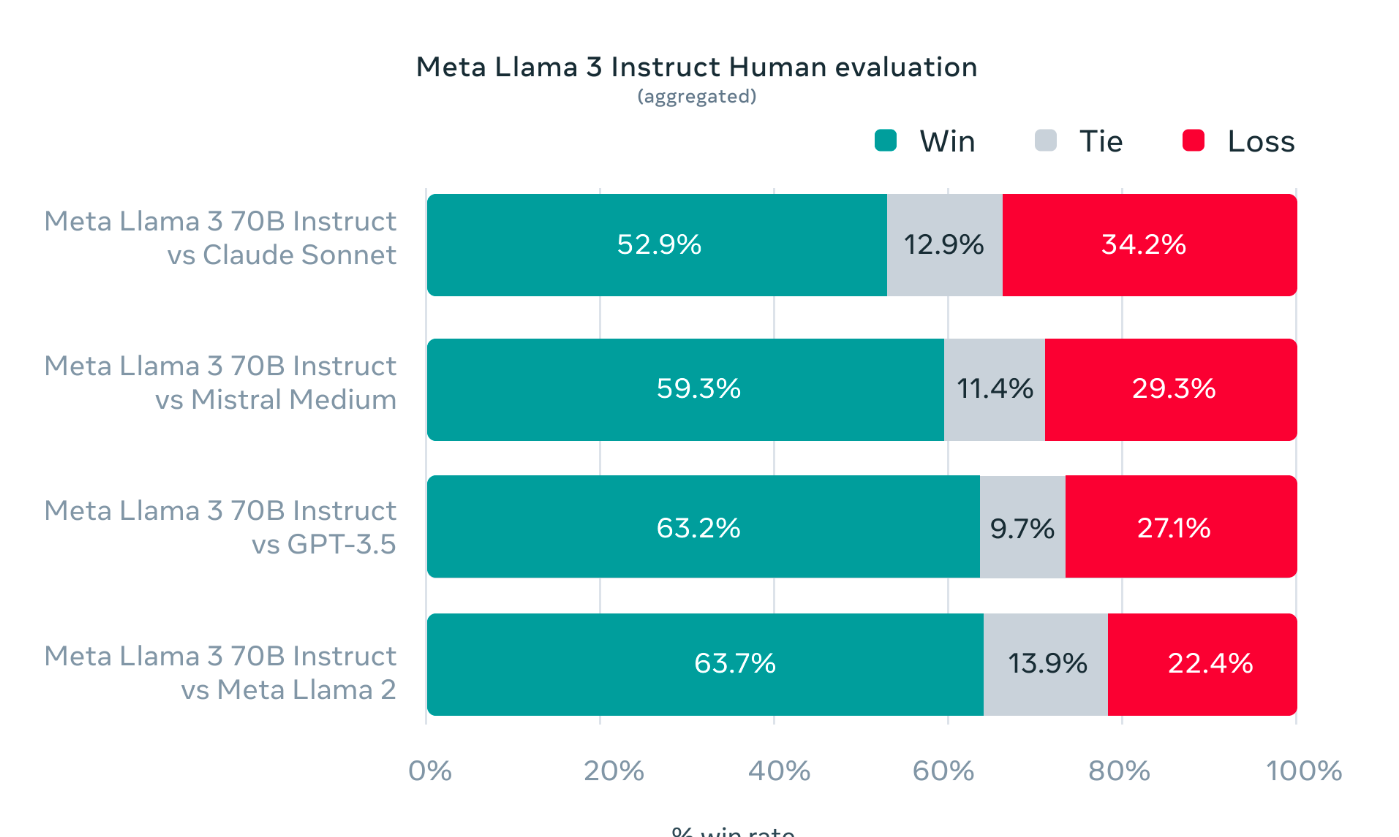
"Meta Llama 3 Instruct 모델 휴먼 평가 결과"
또한 MMLU, GPQA, HumanEval 등 다양한 벤치마크에서도 Llama 3 Instruct 모델의 우수한 성능이 입증되었습니다.
"Meta Llama 3 Instruct 모델 성능 벤치마크"
Responsible AI 노력
Meta는 Llama 3 개발에 있어 책임감있는 AI 개발을 위해 노력했습니다.
- 개발 초기 단계부터 위험 평가 및 완화 수행
- 자체 Responsible AI 프레임워크 따라 모델 개발
- 유해성 테스트 위한 레드팀 운영 및 안전성 강화
- 책임감있는 오픈소스 공개 통한 연구 협력 도모
맺으며
Llama 3는 기존 최고 수준의 언어 모델들과 견줄만한 성능을 보여주었습니다. 개선된 아키텍처와 방대한 사전학습 데이터, 혁신적인 instruction tuning 기법이 성공 요인으로 분석됩니다.
400B 이상 파라미터 버전과 다국어/멀티모달 지원 등 지속적인 발전이 예고된 만큼, Llama 3가 자연어 처리 분야에 가져올 변화가 주목됩니다.
아울러 오픈소스 공개를 통해 연구 커뮤니티와 협력하는 Meta의 개방적 접근 방식도 높이 평가할 만합니다.
댓글
댓글 쓰기