데이터 시각화 [팁]

데이터 분석에서 시각화가 차지하는 비중과 중요성은 아무리 강조해도 지나치지 않습니다. 방대하고 복잡한 데이터 속에 숨겨진 패턴과 인사이트를 한눈에 파악할 수 있게 해주는 것이 바로 시각화의 힘입니다. 아무리 정교한 분석 모델을 동원했다 하더라도, 그 결과를 효과적으로 전달하지 못한다면 데이터 분석의 가치는 반감될 수밖에 없습니다.
그런데 문제는 데이터 시각화 자체가 전문적인 영역이라는 것입니다. 다양한 시각화 도구와 라이브러리를 익히고, 목적에 맞는 차트와 그래프를 선택하여 구현하는 일은 결코 쉽지 않습니다. 특히 데이터 분석가로서는 통계 지식은 있지만, 코딩 스킬이 부족한 경우가 많아 시각화 작업에 어려움을 겪곤 합니다.
이런 상황에서 Claude와 같은 AI 도구는 데이터 시각화에 획기적인 솔루션을 제시합니다. 비록 Claude 자체에 시각화 기능이 내장되어 있지는 않지만, 분석가가 의도한 시각화 결과물을 자연어로 설명하기만 하면 Claude가 이를 구현할 수 있는 파이썬 코드를 자동 생성해주기 때문입니다.
여기서 Claude가 파이썬 코드를 활용하는 이유는 무엇일까요? 그것은 파이썬이 데이터 분석과 시각화에 가장 최적화된 언어이기 때문입니다. Matplotlib, Seaborn, Plotly 등 강력한 시각화 라이브러리를 기본으로 제공하고, Pandas, Numpy 등을 통해 데이터 핸들링도 손쉽게 할 수 있어 데이터 분석가들이 가장 선호하는 언어로 자리매김했습니다.
그러나 파이썬의 장점에도 불구하고 프로그래밍 문법을 익히고 라이브러리 사용법을 학습하는 일은 분석가에겐 부담이 될 수밖에 없었습니다. 바로 이런 간극을 메워주는 것이 Claude입니다. 분석가가 "2022년 월별 매출 추이를 선 그래프로 나타내줘" 라고 요청하기만 하면 Claude가 이를 구현하는 파이썬 코드를 생성해주는 식이죠.
Claude를 통해 자연어로 시각화를 지시하면, 매번 차트 유형을 고민하거나 복잡한 코드를 작성할 필요가 없습니다. 데이터 속성에 맞는 적절한 그래프와 차트를 제안 받을 수 있고, 색상, 레이블, 사이즈 등 세부 사항도 자연어로 조정할 수 있습니다. 마치 그래픽 전문가에게 의뢰하듯 간단한 지시만으로 원하는 시각화 결과물을 얻을 수 있게 되는 것이죠.
이는 분석가의 업무 효율성을 획기적으로 높여줄 뿐 아니라, 더 나은 시각화 결과물 도출에도 기여합니다. 수동 코딩에 소요되던 시간과 노력을 아낄 수 있어 더 다양한 시각화 아이디어를 실험할 수 있게 되고, 이는 곧 인사이트 발견 확률을 높이는 선순환으로 이어지기 때문입니다.
물론 Claude가 제안한 파이썬 코드를 무비판적으로 활용해서는 안 될 것입니다. 분석가로서 시각화의 기본 원리는 알고 있어야 하고, 때로는 코드를 수정하거나 기능을 추가해야 할 수도 있습니다. 그러나 학습의 과정에서도 Claude는 좋은 조력자가 되어줄 것입니다. 자연어로 궁금한 점을 물으면 친절하게 설명해주고 예제 코드도 만들어주니까요.
이처럼 Claude는 파이썬이라는 강력한 시각화 도구의 진입 장벽을 크게 낮춰주는 혁신적인 솔루션입니다. 누구나 자연어 대화만으로 손쉽게 파이썬 시각화 코드를 생성하고, 그 결과를 바로 활용할 수 있게 된 것이죠. 덕분에 데이터 분석의 마지막 단계인 시각화에서 느끼던 부담감에서도 자유로워질 수 있게 되었습니다.
앞으로 Claude와 같은 AI 도구는 데이터 기반 의사결정의 필수 요소인 시각화 작업에서 점점 더 큰 역할을 담당하게 될 것입니다. 단순히 그래프를 그려주는 수준을 넘어, 전달하고자 하는 메시지에 맞는 최적의 시각화 방식을 제안하고 구현해주는 인텔리전트한 방향으로 진화할 것이기 때문이죠.
데이터 분석의 최종 목적은 데이터에서 추출한 인사이트를 의사결정에 반영하고 실행에 옮기는 것입니다. 그 과정의 핵심에는 항상 효과적인 소통과 설득이 자리하고 있죠. 그리고 그 소통과 설득의 중심에는 언제나 시각화가 있습니다. Claude는 바로 그 시각화의 힘을 모두가 쉽게 활용할 수 있도록 만들어주는 데이터 분석의 든든한 파트너인 셈입니다.
가상의 시나리오를 통해 데이터를 시각화하는 과정을 살펴보겠습니다.
(시나리오)
모바일 게임 개발사 A의 데이터 분석가 John은 신규 게임 이용자들의 행동 패턴 분석 보고서를 작성하고 있습니다. 게임 내 각종 이벤트 참여와 구매 행위 간의 상관관계를 분석한 결과, 흥미로운 인사이트를 발견했습니다. 이를 보고서에 시각화해서 넣고 싶지만 막상 코딩은 자신이 없었죠.
John은 우선 시각화하고 싶은 내용을 정리하여 Claude에게 다음과 같이 요청합니다.
프롬프트: "분석 결과에 따르면 이벤트 A에 참여한 신규 이용자들의 구매 금액이 비참여자들에 비해 50% 이상 높았습니다. 이벤트 A의 효과를 보여주는 막대그래프를 만들어 주시겠습니까? x축은 신규 이용자 그룹(참여자 vs 비참여자)을 나타내고, y축은 첫 주 평균 구매액을 나타내도록 해주세요. 영문 레이블을 사용하여 Python 코드를 생성해 주시기 바랍니다.”
Claude는 John이 원하는 시각화를 위한 파이썬 코드를 다음과 같이 생성해 줍니다.
import matplotlib.pyplot as plt
import numpy as np
labels = ['이벤트 A 참여', '이벤트 A 비참여']
purchase_amounts = [15000, 9000]
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(8, 5))
rects = ax.bar(x, purchase_amounts, width)
ax.set_title('신규 이용자의 이벤트 A 참여 여부에 따른 첫 주 평균 구매액', fontsize=16)
ax.set_ylabel('첫 주 평균 구매액 (원)', fontsize=12)
ax.set_xticks(x)
ax.set_xticklabels(labels)
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:,}',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects)
fig.tight_layout()
plt.show()
위 파이썬 코드를 실행한 결과입니다.
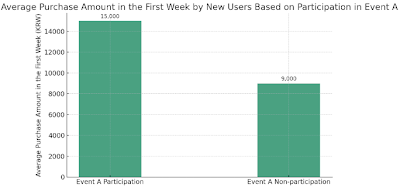
John은 Claude가 제안한 코드를 실행해보고 놀라움을 금치 못했습니다. 불과 1~2줄의 자연어 설명만으로 그가 머릿속으로 그려왔던 바로 그 차트가 만들어진 것입니다. 막대의 높이 차이로 이벤트의 효과성이 명확하게 드러났고, 평균 구매액까지 깔끔하게 표기되어 있었습니다. .
이에 고무된 John은 분석 보고서에 몇 가지 차트를 더 추가하기로 마음먹었습니다.
프롬프트: "이벤트 A 참여자 중에서도 구매액이 가장 높은 상위 5% 고객들의 특성이 궁금해. 이 VIP 고객들의 성별, 연령대, 접속 기기별 비중을 파이 차트를 그려주세요. 영문 레이블을 사용하여 Python 코드를 생성해 주시기 바랍니다”
John의 추가 요청에 Claude는 금세 파이 차트용 파이썬 코드를 만들어 냅니다. gender_labels, gender_sizes 등의 변수명까지 John의 요구사항에 맞게 알아서 지정하는 센스도 보여주었습니다.
import matplotlib.pyplot as plt
gender_labels = ['남성', '여성']
gender_sizes = [60, 40]
age_labels = ['10대', '20대', '30대', '40대 이상']
age_sizes = [15, 30, 45, 10]
device_labels = ['Android', 'iOS', 'PC']
device_sizes = [50, 45, 5]
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
axs[0].pie(gender_sizes, labels=gender_labels, autopct='%1.1f%%')
axs[0].axis('equal')
axs[0].set_title('성별 분포')
axs[1].pie(age_sizes, labels=age_labels, autopct='%1.1f%%')
axs[1].axis('equal')
axs[1].set_title('연령대 분포')
axs[2].pie(device_sizes, labels=device_labels, autopct='%1.1f%%')
axs[2].axis('equal')
axs[2].set_title('접속 기기 분포')
plt.suptitle('VIP 고객(상위 5%) 속성별 분포', fontsize=16)
plt.tight_layout()
plt.show()
이 파이쎤 코드를 실행한 결과입니다.
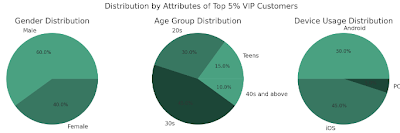
John은 Claude가 제시한 코드를 그대로 실행했고, 결과는 대성공이었습니다. 간결하지만 인사이트가 잘 드러나는 파이 차트 3개가 보고서의 완성도를 한층 높여주었습니다.
John의 경험은 데이터 시각화에서 AI 도구가 어떤 역할을 할 수 있을지 잘 보여줍니다. 분석가가 원하는 차트의 요건만 자연어로 명확하게 전달하면, 나머지 코딩은 Claude와 같은 AI가 도맡아 하는 것이죠. 덕분에 분석가는 파이썬 문법을 공부하는 대신 시각화 아이디어를 더 고민할 수 있게 됩니다.
물론 Claude가 만들어준 코드도 무조건 완벽한 것은 아닙니다. 항상 결과물을 꼼꼼히 확인하고, 필요할 때는 직접 수정해야 할 것입니다. 또한 분석가 스스로도 기본적인 시각화 역량은 갖춰야겠죠. 하지만 그 과정에서도 Claude의 조언은 분명 큰 도움이 될 것입니다.
앞으로 Claude와 같은 AI 도구들은 그래프의 유형을 추천하고, 색상 팔레트를 제안하는 등 데이터 스토리텔링 전반에서 분석가들의 든든한 조력자가 되어줄 것입니다. 지루하고 복잡한 차트 작성 과정을 단순화함으로써, 분석가들이 보다 창의적인 시각화에 도전할 수 있는 환경을 조성해줄것입니다.
Python 코드로 그래프 및 차트 그림 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from plotly import graph_objects as go
# 랜덤 데이터 생성
factories = ['A', 'B', 'C', 'D', 'E']
hours = list(range(1, 11))
production_data = pd.DataFrame({'Factory': np.repeat(factories, 10),
'Hour': hours * 5,
'Production': np.random.randint(50, 100, 50),
'Defect_Rate': np.random.rand(50),
'Utilization': np.random.rand(50)})
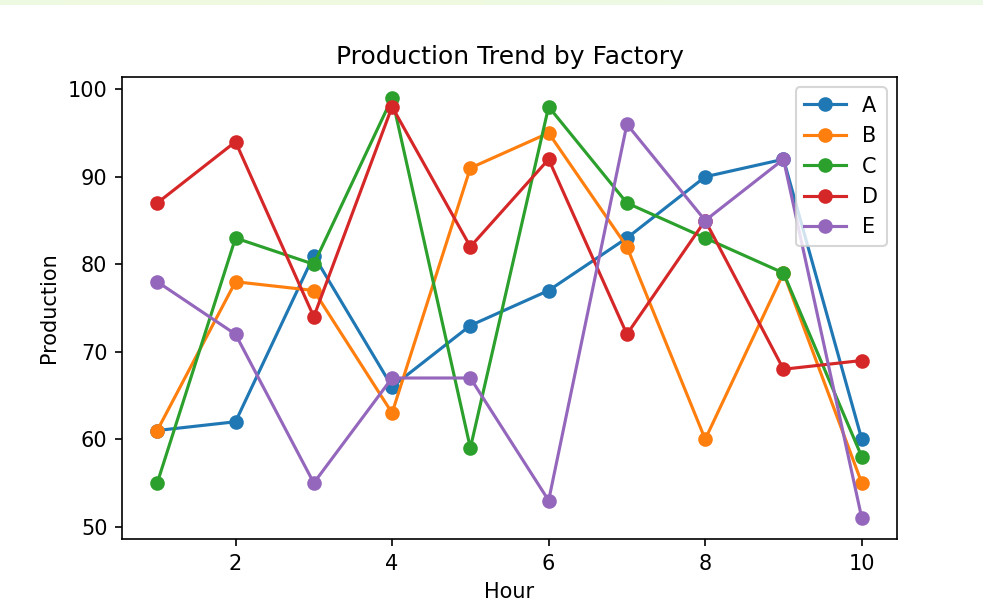
# 꺾은선 그래프 - 생산량 추이
plt.figure(figsize=(10, 6))
for factory in factories:
data = production_data[production_data['Factory'] == factory]
plt.plot(data['Hour'], data['Production'], marker='o', label=factory)
plt.xlabel('Hour')
plt.ylabel('Production')
plt.title('Production Trend by Factory')
plt.legend()
plt.show()
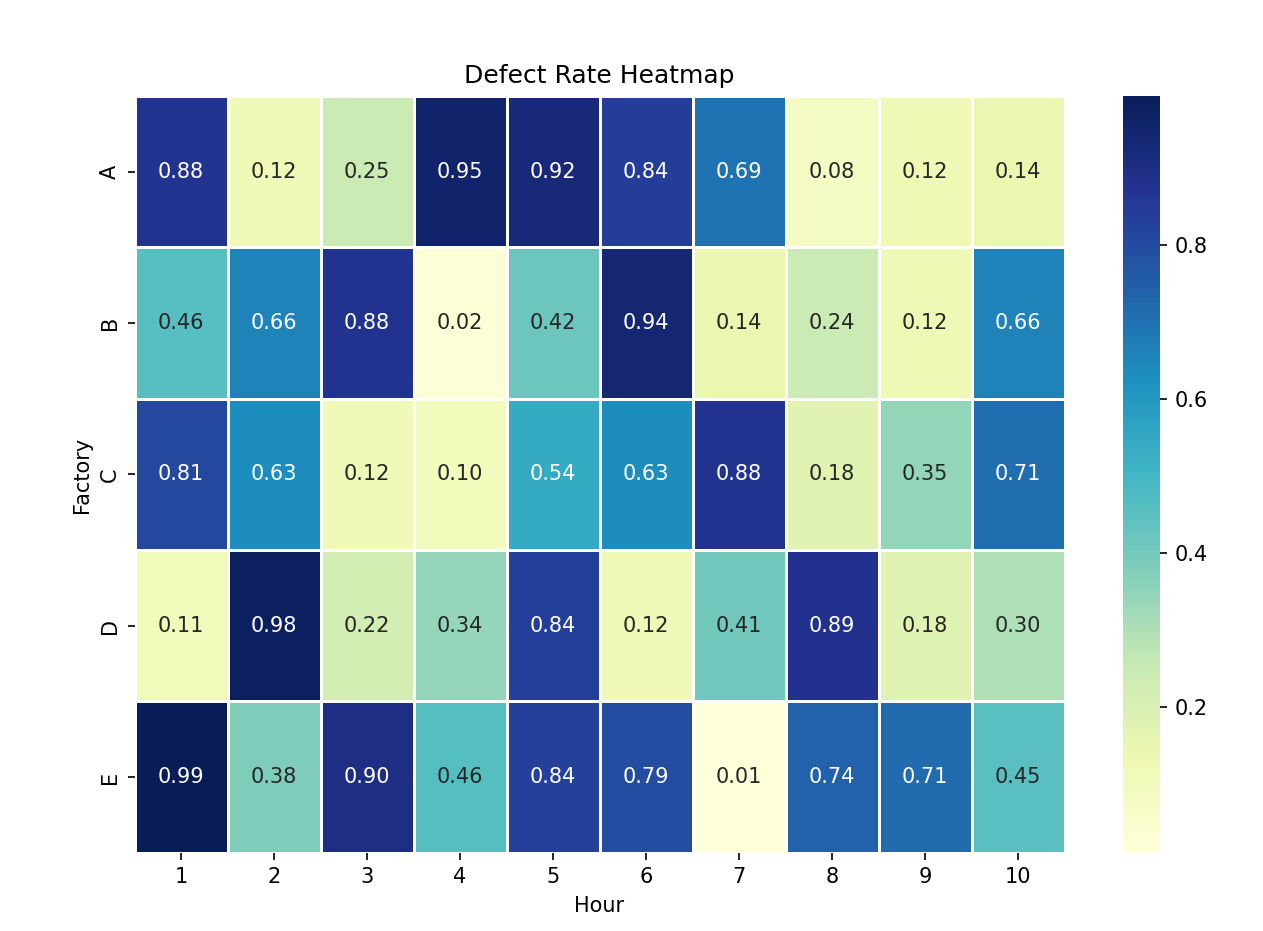
# 히트맵 - 불량률의 시공간적 패턴
defect_rate_matrix = production_data.pivot_table(index='Factory', columns='Hour', values='Defect_Rate')
plt.figure(figsize=(10, 8))
sns.heatmap(defect_rate_matrix, annot=True, cmap='YlGnBu', fmt='.2f', linewidths=0.5)
plt.title('Defect Rate Heatmap')
plt.show()
# 게이지 차트 - 가동률 현황
utilization_data = production_data.groupby('Factory')['Utilization'].mean().reset_index()
utilization_data['Utilization'] = utilization_data['Utilization'] * 100 # 백분율로 변환
fig = go.Figure()
for i in range(len(utilization_data)):
fig.add_trace(go.Indicator(
mode = "gauge+number",
value = utilization_data.iloc[i]['Utilization'],
domain = {'x': [0.2*i, 0.2*(i+1)], 'y': [0, 1]},
title = {'text': utilization_data.iloc[i]['Factory']},
gauge = {
'axis': {'range': [None, 100], 'tickwidth': 1, 'tickcolor': "darkblue"},
'bar': {'color': "darkblue"},
'bgcolor': "white",
'borderwidth': 2,
'bordercolor': "gray",
'steps': [
{'range': [0, 60], 'color': 'lightgray'},
{'range': [60, 100], 'color': 'gray'}],
'threshold': {
'line': {'color': "red", 'width': 4},
'thickness': 0.75,
'value': 90}}))
fig.update_layout(height=400, width=1000, title_text="Factory Utilization Rate")
fig.show()
댓글
댓글 쓰기